The EdgeLab focuses on the research of moving processing from the cloud to the edge.
This topic follows recent industry trends to offload workloads from the cloud and to where data is generated. According to Gartner, by 2025, about 75% of the enterprise data will be generated and processed outside the data centers and the cloud (source).
However, companies realize that the Edge is a complicated environment. In particular, the Edge does not offer data services similar to what the cloud is able to offer.
Our Lab is researching this topic and collaborating with a company called AnyLog that is addressing the challenges that companies are facing at the edge.
We published 2 papers with AnyLog:
AnyLog: a Grand Unification of the Internet of Things in CIDR 2020
And a paper describing the implementation of the technology in CIDR 2024 The Tipping Point of Edge-Cloud Data Management.
Our Lab is leveraging the AnyLog decentralized data management approach in the context of video management and AI. The adoption of AI requires efficient data processing systems. Video and AI bring huge efficiencies and value. For example, in traffic monitoring, self checkout in retail stores, security applications, and asset management (with drones). However, moving large volumes of video streams to the cloud is not economical and in many cases not feasible.
The lab will demonstrate data management of video streams at the edge (without centralizing the data) and the integration to AI at the Edge.
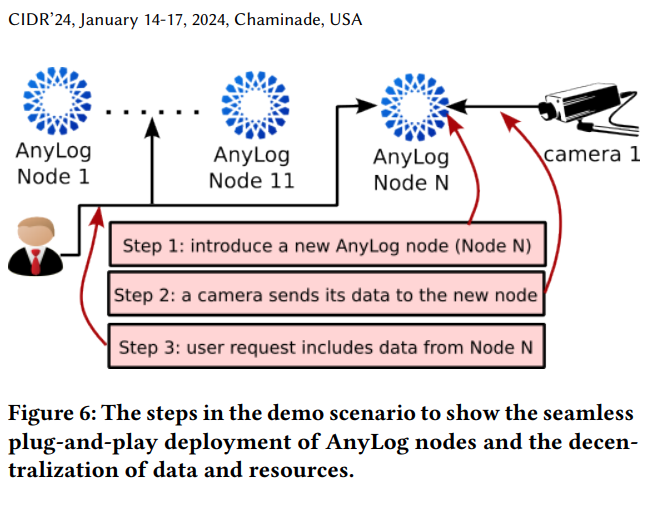
Here are some of the characteristics we plan to demonstrate:
- Monitor the distributed edge data and resources from a single point – making the edge a cloud like environment.
- Completely Decentralized architecture.
- Data remains at the edge. No massive data transfers.
- No Cloud cost/contracts.
- Real-Time.
- Data (the video streams and the inference AI data) remains in full control of the data owners.
- Data is Secured – Using keys to sign messages and data.
- Authentication and permission policies.
- High Availability by replicating data between edge nodes
- Using rule engines to make the edge nodes self-managed and extract insights and alerts from the data and AI insights.
The diagram below shows how data is managed to facilitate AI at the edge (without dependency on centralization):
At the collection point:
- Data is first collected by sensors and cameras. We use AnyLog as the data platform that collects the data using a variety of APIs (like REST, MQTT, gRPC).
At the training point:
- The training application queries the needed edge data as if the data is centralized. We use AnyLog to provide a virtual unified view of the distributed data (and the video images) that is queryable using SQL.
- The training application generates a machine learning model based on the analyzed data and video.
At the execution point:
- The model is pushed to the edge and executed. AnyLog provides a continuous stream of unified data to the model.
- The model generates predictions which are hosted locally at the edge. AnyLog provides insights as if the distributed predictions are unified and centralized.
At the control point:
- AnyLog rule engines evaluate the predictions and triggers alerts.
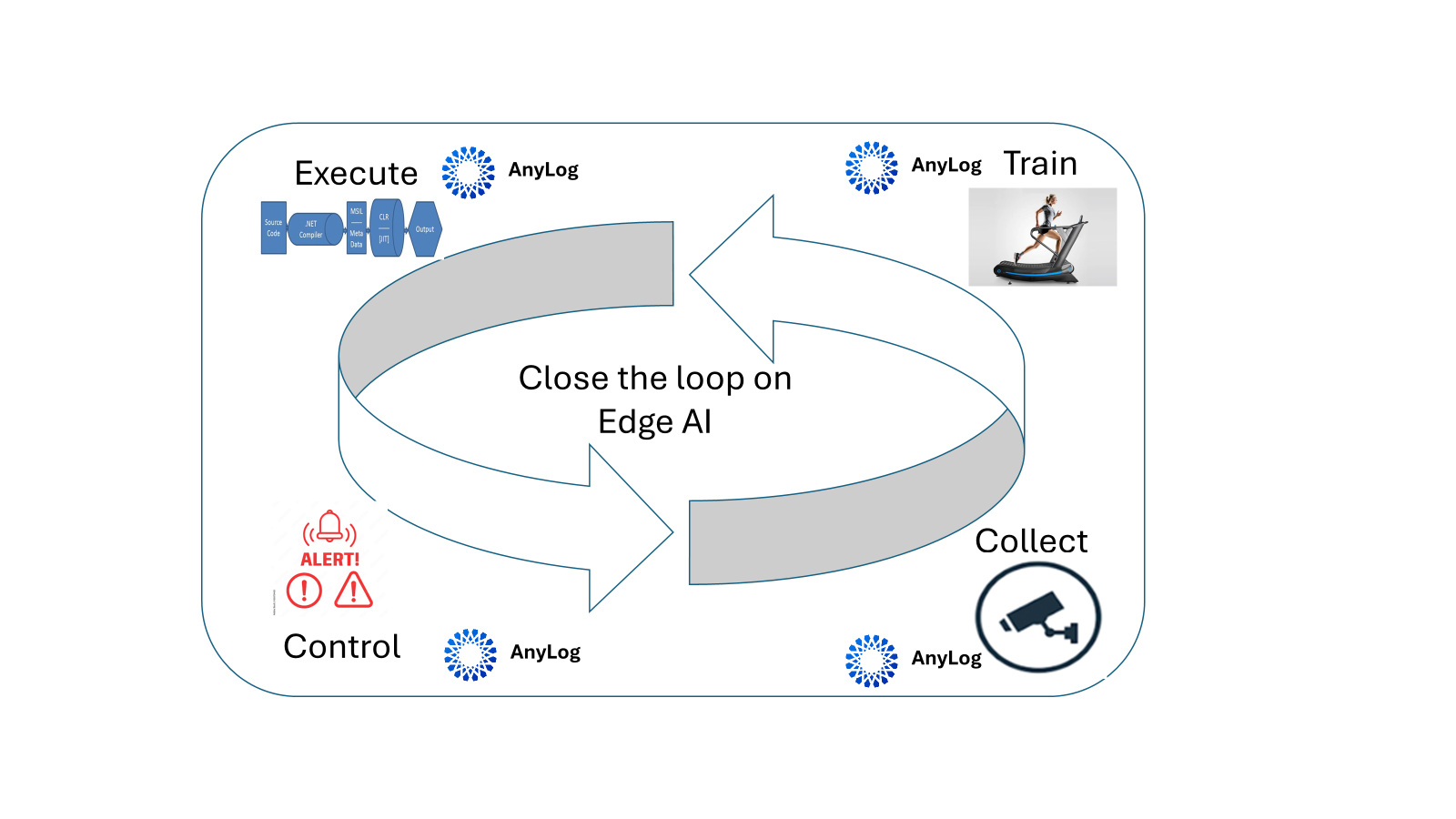
With the proper alerts, the behavior changes and impacts the data generated to create an updated model. This process continues repeatedly.
It is a unique process – it brings real-time, efficiency and cost savings and replaces long and tedious engineering effort with automation.